FastPose-ViT: A Vision Transformer for Real-Time Spacecraft Pose Estimation
Pierre Ancey, Andrew Price, Saqib Javed, Mathieu Salzmann
Abstract
Estimating the 6-degrees-of-freedom (6DoF) pose of a spacecraft from a single image is critical for autonomous operations like in-orbit servicing and space debris removal. Existing state-of-the-art methods often rely on iterative Perspective-n-Point (PnP)-based algorithms, which are computationally intensive and ill-suited for real-time deployment on resource-constrained edge devices.
To overcome these limitations, we propose FastPose-ViT, a Vision Transformer (ViT)-based architecture that directly regresses the 6DoF pose. Our approach processes cropped images from object bounding boxes and introduces a novel mathematical formalism to map these localized predictions back to the full-image scale. This formalism is derived from the principles of projective geometry and the concept of "apparent rotation", where the model predicts an apparent rotation matrix that is then corrected to find the true orientation.
We demonstrate that our method outperforms other non-PnP strategies and achieves performance competitive with state-of-the-art PnP-based techniques on the SPEED dataset. Furthermore, we validate our model's suitability for real-world space missions by quantizing it and deploying it on power-constrained edge hardware. On the NVIDIA Jetson Orin Nano, our end-to-end pipeline achieves a latency of ~75 ms per frame under sequential execution, and a non-blocking throughput of up to 33 FPS when stages are scheduled concurrently.
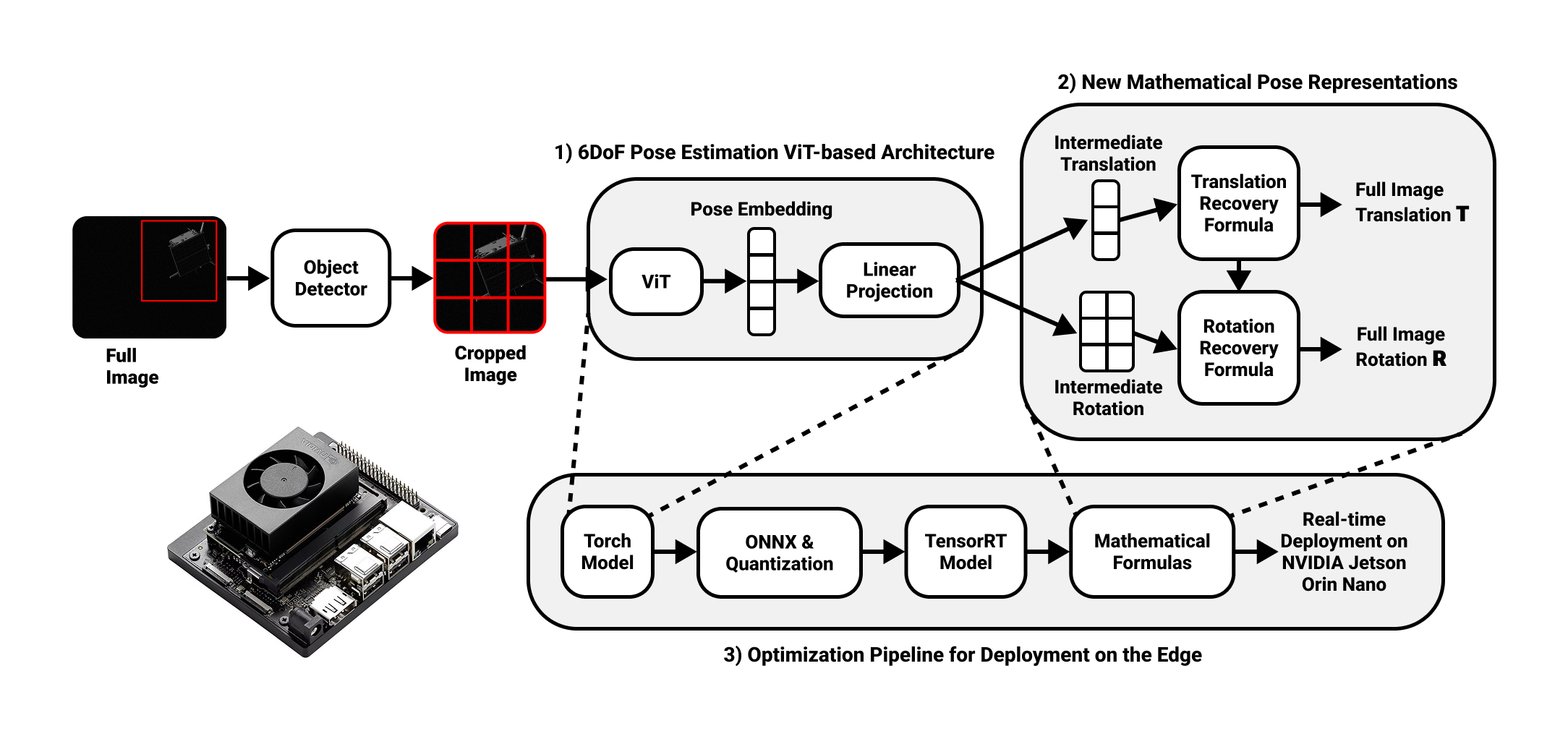
Method Overview
FastPose-ViT is a two-stage pipeline that first detects the spacecraft, then directly regresses its 6DoF pose without iterative solvers.
Object Detection
A lightweight detector (LW-DETR) localizes the spacecraft bounding box in the full image.
Cropping
The image is cropped to the bounding box, focusing network attention on the object and avoiding resolution loss from downscaling.
ViT Backbone
The crop is split into patches and processed by a Vision Transformer (ViT-B) pretrained on ImageNet.
Direct Regression
A linear projection head replaces the classification MLP, outputting normalized pose parameters directly.
Geometric Reformulation
The core contribution of this work is a novel mathematical formalism that enables accurate pose recovery from cropped images. This addresses a fundamental challenge: predictions made on a crop must be mapped back to the full-image coordinate system.
Apparent Rotation
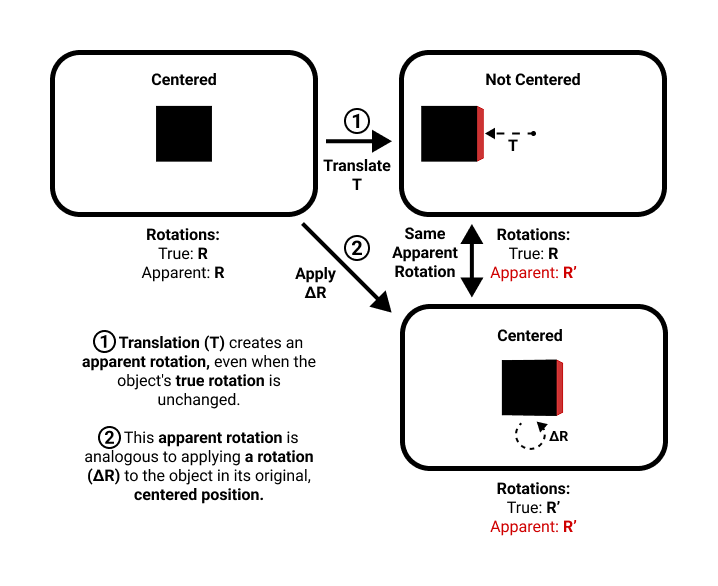
Perspective projection causes an object's perceived orientation to change based on where it appears in the frame. An off-center object looks rotated compared to the same object at the image center.
We define the apparent rotation R' as the orientation a centered object would need to have to visually match the off-center target. The network predicts this apparent rotation from the crop.
To recover the true rotation R, we apply a corrective rotation ΔR derived from the predicted translation vector and the optical axis using Rodrigues' rotation formula:
Normalized Translation Targets
Instead of regressing absolute translation T = (tx, ty, tz), the model predicts normalized coordinates (Ux, Uy, Uz) relative to the crop dimensions.
Depth Proxy (Uz)
Cropping acts as a "digital zoom". The scaling factors between the original bounding box and the resized crop encode depth information.
Lateral Offsets (Ux, Uy)
These account for the displacement between the object's true center and the crop center, enabling recovery of full-image coordinates.
This normalization makes predictions invariant to crop size and position, allowing the network to generalize across different bounding box detections.
Results
Evaluated on the SPEED dataset, FastPose-ViT sets a new state-of-the-art for non-PnP methods and remains competitive with iterative PnP-based approaches.
| Method | Type | ET [m] | ER [deg] |
|---|---|---|---|
| FastPose-ViT (Ours) | Direct | 0.0221 | 0.4183 |
| Chen et al. | PnP | 0.0320 | 0.4100 |
| Gerard et al. | PnP | 0.0730 | 0.9100 |
| URSONet | Direct | 0.1450 | 2.4900 |
vs. Direct Methods
6.5x lower translation error and 6x lower rotation error compared to URSONet, the previous best non-PnP approach.
Ablation Insight
Training from scratch increases rotation error by 10x. ImageNet pre-training is essential for convergence.
Edge Deployment
Real spacecraft operate under strict power budgets (typically 1-25W). We validated our pipeline on representative edge hardware to demonstrate mission readiness.
Optimization Pipeline
Tested on NVIDIA Jetson Orin Nano in 25W mode. The detector and pose network can be scheduled concurrently for maximum throughput, or run sequentially when latency is critical.
Citation
@InProceedings{Ancey_2026_WACV,
author = {Ancey, Pierre and Price, Andrew and Javed, Saqib and Salzmann, Mathieu},
title = {FastPose-ViT: A Vision Transformer for Real-Time Spacecraft Pose Estimation},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {March},
year = {2026},
pages = {7873-7882}
}